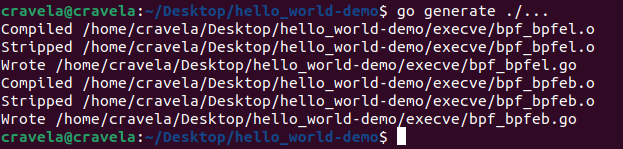
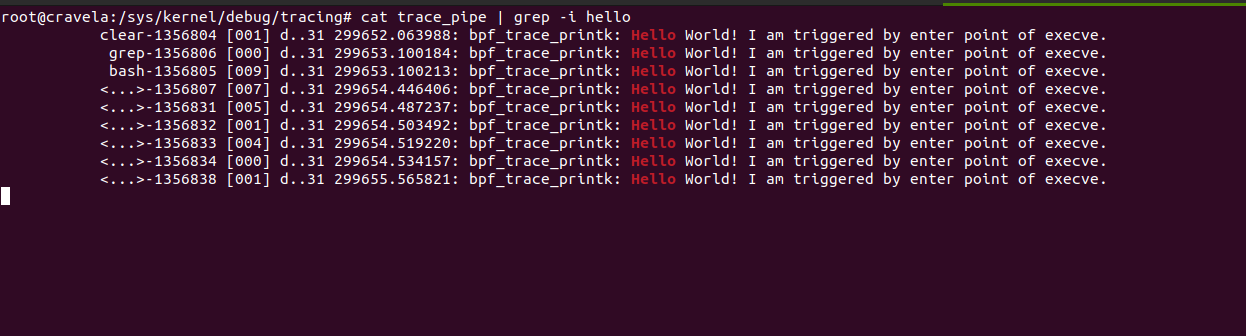
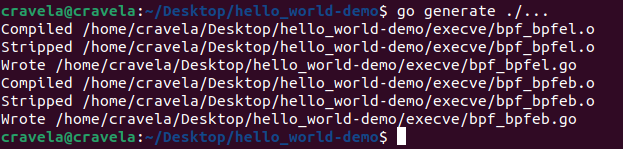
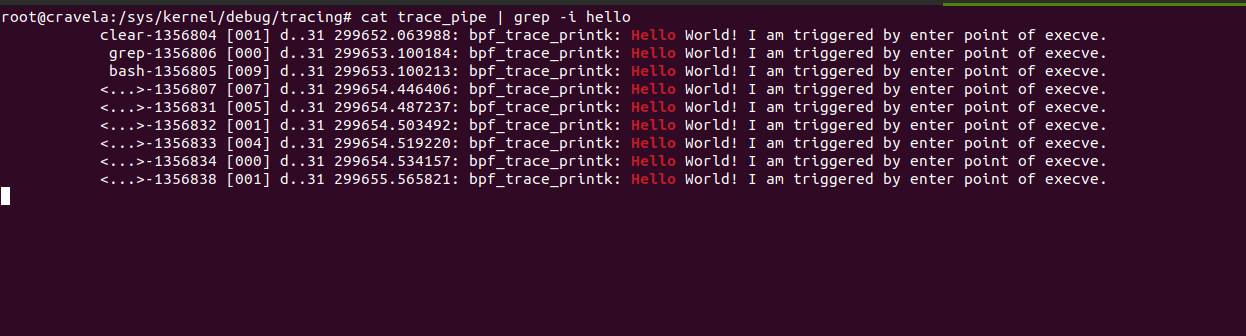
The provided eBPF kernel-side program is a kprobe program attached to the __x64_sys_tcp_connect function, which is a system call handler for tcp_connect on x64 systems. Let’s go through the program step by step:
SEC("kprobe/__x64_sys_tcp_connect")
int kprobe__tcp_connect(struct pt_regs *ctx)
{
struct sock *sk = (struct sock *)PT_REGS_PARM1(ctx);
struct sock_common conn = READ_KERN(sk->__sk_common);
struct sockaddr_in sockv4;
struct sockaddr_in6 sockv6;
sys_context_t context = {};
args_t args = {};
u64 types = ARG_TYPE0(STR_T) | ARG_TYPE1(SOCKADDR_T);
init_context(&context);
context.argnum = get_arg_num(types);
context.retval = PT_REGS_RC(ctx);
if (context.retval >= 0 && drop_syscall(_NETWORK_PROBE))
{
return 0;
}
if (get_connection_info(&conn, &sockv4, &sockv6, &context, &args, _TCP_CONNECT) != 0)
{
return 0;
}
args.args[0] = (unsigned long)conn.skc_prot->name;
set_buffer_offset(DATA_BUF_TYPE, sizeof(sys_context_t));
bufs_t *bufs_p = get_buffer(DATA_BUF_TYPE);
if (bufs_p == NULL)
return 0;
save_context_to_buffer(bufs_p, (void *)&context);
save_args_to_buffer(types, &args);
events_perf_submit(ctx);
return 0;
}
The program starts with the definition of the kprobe function kprobe__tcp_connect, which takes a pointer to struct pt_regs (ctx) as an argument.
The program declares and initializes several variables:
struct sock *sk:
struct sock *sk = (struct sock *)PT_REGS_PARM1(ctx);
It represents the socket object obtained from the first parameter of the system call.It retrieves the socket object from the function arguments and stores it in the sk variable for further processing within the eBPF program.
PT_REGS_PARM1(ctx):
This macro is used to access the value of the second parameter (parm1) of the function, which is represented by the ctx pointer to struct pt_regs.
(struct sock *):
The obtained value from PT_REGS_PARM1(ctx) is cast to a pointer of type struct sock *. This is done to interpret the value as a socket object.
struct sock *sk:
This line declares a variable named sk of type struct sock * and assigns the obtained socket object to it.
struct sock_common conn:
struct sock_common conn = READ_KERN(sk->__sk_common);
- It is used to read the value of the
__sk_common field from the sk socket object and store it in a struct sock_common variable named conn.
Let’s break down the code:
sk->__sk_common: This accesses the __sk_common field within the sk socket object. The __sk_common field is a member of the sk structure and represents the common data shared by different socket types.
READ_KERN(...): The READ_KERN macro is used to read kernel memory. In this case, it reads the value of sk->__sk_common from the kernel memory space.
struct sock_common conn: This line declares a variable named conn of type struct sock_common and assigns the value read from sk->__sk_common to it.
This allows subsequent access to the common socket information for further processing within the eBPF program.
struct sockaddr_in sockv4 and struct sockaddr_in6 sockv6
struct sockaddr_in sockv4;
struct sockaddr_in6 sockv6;
- The lines
struct sockaddr_in sockv4; and struct sockaddr_in6 sockv6; declare two variables, sockv4 and sockv6, respectively. These variables are of types struct sockaddr_in and struct sockaddr_in6, which are used to represent socket addresses for IPv4 and IPv6 protocols.
Here’s a brief explanation of these structures:
struct sockaddr_in:
- This structure is defined in the <netinet/in.h> header file.
- It represents an
IPv4 socket address. - It has the following members:
sin_family: The address family, which is typically set to AF_INET for IPv4.sin_port: The port number associated with the socket address.sin_addr: The IPv4 address, stored as an in_addr structure.sin_zero: Padding to ensure structure alignment.
struct sockaddr_in6:
- This structure is also defined in the <netinet/in.h> header file.
- It represents an
IPv6 socket address. - It has the following members:
sin6_family: The address family, usually set to AF_INET6 for IPv6.sin6_port: The port number associated with the socket address.sin6_flowinfo: IPv6 flow information.sin6_addr: The IPv6 address, stored as an in6_addr structure.sin6_scope_id: Scope ID for link-local addresses.sin6_padding: Padding for future use.
In the given code, the variables sockv4 and sockv6 are declared to store socket addresses of type IPv4 and IPv6, respectively. These variables used in the get_connection_info function to populate the socket address information based on the connection details being processed by the eBPF program.
- Here’s a brief explanation of these lines:
sys_context_t context = {};
args_t args = {};
The lines sys_context_t context = {}; and args_t args = {}; declare and initialize variables context and args, respectively, with empty or zero-initialized values.
sys_context_t context = {};:
- This line declares a variable named
context of type sys_context_t. - The
sys_context_t type is a user-defined structure or typedef representing the context or state of the system. - The {} initializer initializes the context variable, setting all its members to their default or zero values.
This line is commonly used to ensure that the context variable starts with default values before being populated or used further in the program.
- This line declares a variable named
args of type args_t. - The
args_t type is a user-defined structure or typedef representing arguments or parameters used in a certain context or function. - The {} initializer initializes the args variable, setting all its members to their default or zero values.
Similar to the previous line, this initialization ensures that the args variable starts with default values before being assigned or utilized in subsequent program logic.
By initializing these variables to empty or zero values, it provides a clean and consistent starting point for the context and args structures, allowing them to be populated with specific data as required by the program’s logic.
- Here’s a brief explanation of these lines:
u64 types = ARG_TYPE0(STR_T) | ARG_TYPE1(SOCKADDR_T);
The line u64 types = ARG_TYPE0(STR_T) | ARG_TYPE1(SOCKADDR_T); defines a variable types of type u64(unsigned 64-bit integer) and assigns it a value calculated using the macros ARG_TYPE0() and ARG_TYPE1().
// Definition of ENC_ARG_TYPE,ARG_TYPE0
#define MAX_ARGS 6
#define ENC_ARG_TYPE(n, type) type << (8 * n)
#define ARG_TYPE0(type) ENC_ARG_TYPE(0, type)
#define ARG_TYPE1(type) ENC_ARG_TYPE(1, type)
#define ARG_TYPE2(type) ENC_ARG_TYPE(2, type)
#define ARG_TYPE3(type) ENC_ARG_TYPE(3, type)
#define ARG_TYPE4(type) ENC_ARG_TYPE(4, type)
#define ARG_TYPE5(type) ENC_ARG_TYPE(5, type)
#define DEC_ARG_TYPE(n, type) ((type >> (8 * n)) & 0xFF)
Here
#define ARG_TYPE0(type) ENC_ARG_TYPE(0, type)
The macro ENC_ARG_TYPE(n, type) is defined with the purpose of encoding an argument type type at a specific position n within a 64-bit value. Here’s a breakdown of how it works:
The macro definition ENC_ARG_TYPE(n, type) type << (8 * n) consists of two parts:
type: It represents the argument type that needs to be encoded. It is provided as an argument to the macro.
<< (8 * n): It performs a left shift operation on the type value by 8 * n bits. This shift operation moves the bits of type to the left by a certain number of positions determined by n.
- The value 8 corresponds to the number of bits occupied by one byte.
- The variable n determines the position within the 64-bit value where the type will be encoded.
- Multiplying 8 by n calculates the number of bits by which the type value should be shifted to the left to occupy the desired position.
The resulting value of type after the left shift operation represents the encoded argument type at the specified position n within the 64-bit value.
#define ARG_TYPE0(type) ENC_ARG_TYPE(0, type)
The macro ARG_TYPE0(type) is defined as a convenience macro that uses the ENC_ARG_TYPE(n, type) macro to encode an argument type type at position 0 within a 64-bit value. Here’s how it works:
The macro definition ARG_TYPE0(type) ENC_ARG_TYPE(0, type) expands to the following:
ENC_ARG_TYPE(0, type): This macro is called with arguments 0 and type, which represents the position and type of the argument to be encoded.
ENC_ARG_TYPE(n, type) type << (8 * n): The ENC_ARG_TYPE(n, type) macro is invoked with 0 as the position n and type as the argument type. It performs a left shift operation on the type value by 8 * 0 bits, effectively encoding the type at position 0.
In summary, ARG_TYPE0(type) is a shorthand macro that encodes the argument type type at position 0 within a 64-bit value. It simplifies the encoding process by providing a clear and concise way to specify the position of the argument type. The resulting encoded value can be used as a bitmask or flag to represent the argument type within the program.
These macros allow for convenient encoding and decoding of argument types used in the program. Here’s a breakdown of the relevant macros and their corresponding type values:
ARG_TYPE0(type): This macro takes an argument type (type)and encodes it at position 0. It uses the ENC_ARG_TYPE(n, type) macro to calculate the encoded value by shifting the type value type by 8 * n bits, where n is the position.ARG_TYPE1(type): Similar to ARG_TYPE0, but encodes the type at position 1.
In this specific case, STR_T and SOCKADDR_T are type values associated with string and socket address types, respectively.
The | operator is used to perform a bitwise OR operation between the encoded values of STR_T and SOCKADDR_T, resulting in a combined type value.
Finally, the combined type value is assigned to the types variable of type u64. The types variable can now be used as a bitmask or flag to represent multiple argument types within the program.
The line init_context(&context); is a function call that invokes the init_context function and passes the address of the context variable as an argument. This call initializes the sys_context_t object context by populating its members with relevant information based on the current task.
By calling init_context(&context);, the context object is prepared to store context-specific information such as the timestamp, process IDs, parent process ID, user ID, and command name associated with the current task. Once the function call completes, the context object will hold the initialized values, ready for further use or analysis in the program.
#define TASK_COMM_LEN 16
typedef struct __attribute__((__packed__)) sys_context
{
u64 ts;
u32 pid_id;
u32 mnt_id;
u32 host_ppid;
u32 host_pid;
u32 ppid;
u32 pid;
u32 uid;
u32 event_id;
u32 argnum;
s64 retval;
char comm[TASK_COMM_LEN];
} sys_context_t;
- The code snippet provided defines a data structure called
sys_context_t, which represents the context information associated with a system event. The sys_context_t structure has the following members:
- ts: Represents the
timestamp of the event. - pid_id and mnt_id: Store the
process ID, namespace ID and mount namespace ID, respectively. - host_ppid and host_pid: Store the
parent process ID and process ID of the host. - ppid and pid: Store the
parent process ID and process ID within the container or host, depending on the configuration. - uid: Represents the
user ID associated with the event. - event_id: Represents the
ID of the event. - argnum: Indicates the
number of arguments associated with the event. - retval: Stores the
return value of the event. - comm: Represents the command name associated with the task, stored as a character array with a maximum length defined by
TASK_COMM_LEN.
// == Context Management == //
static __always_inline u32 init_context(sys_context_t *context)
{
struct task_struct *task = (struct task_struct *)bpf_get_current_task();
context->ts = bpf_ktime_get_ns();
context->host_ppid = get_task_ppid(task);
context->host_pid = bpf_get_current_pid_tgid() >> 32;
#if defined(MONITOR_HOST)
context->pid_id = 0;
context->mnt_id = 0;
context->ppid = get_task_ppid(task);
context->pid = bpf_get_current_pid_tgid() >> 32;
#else // MONITOR_CONTAINER or MONITOR_CONTAINER_AND_HOST
u32 pid = get_task_ns_tgid(task);
if (context->host_pid == pid)
{ // host
context->pid_id = 0;
context->mnt_id = 0;
context->ppid = get_task_ppid(task);
context->pid = bpf_get_current_pid_tgid() >> 32;
}
else
{ // container
context->pid_id = get_task_pid_ns_id(task);
context->mnt_id = get_task_mnt_ns_id(task);
context->ppid = get_task_ns_ppid(task);
context->pid = pid;
}
#endif /* MONITOR_CONTAINER || MONITOR_HOST */
context->uid = bpf_get_current_uid_gid();
bpf_get_current_comm(&context->comm, sizeof(context->comm));
return 0;
}
The provided code snippet is a continuation of the previous code. It includes the implementation of the init_context function, which is responsible for initializing the sys_context_t structure with relevant context information.
Let’s go through the code step by step:
struct task_struct *task = (struct task_struct *)bpf_get_current_task();: This line retrieves the current task (process) using the bpf_get_current_task() BPF helper function. It casts the task to the task_struct structure.
context->ts = bpf_ktime_get_ns();: This line assigns the current timestamp, obtained using the bpf_ktime_get_ns() BPF helper function, to the ts member of the context structure.
3.context->host_ppid = get_task_ppid(task);: This line retrieves the parent process ID (PPID) of the current task using the get_task_ppid() function and assigns it to the host_ppid member of the context structure.
context->host_pid = bpf_get_current_pid_tgid() >> 32;: This line retrieves the process ID (PID) and thread group ID (TGID) of the current task using the bpf_get_current_pid_tgid() BPF helper function. It shifts the 64-bit value right by 32 bits to obtain the PID and assigns it to the host_pid member of the context structure.
The code block starting with #if defined(MONITOR_HOST) and ending with #else or #endif is conditional compilation based on the presence of the MONITOR_HOST macro. Depending on the configuration, the code inside the corresponding block will be included in the final program.
If MONITOR_HOST is defined, the code block inside #if defined(MONITOR_HOST) is executed. It sets pid_id and mnt_id to 0, indicating that the current task is running in the host environment. It also assigns the host PPID and PID to ppid and pid members, respectively.
If MONITOR_HOST is not defined, the code block inside #else or #endif is executed. It checks if the host_pid is equal to the PID obtained from the task’s namespace (pid). If they are equal, it means the current task is running in the host environment. In that case, pid_id and mnt_id are set to 0, and the host PPID and PID are assigned to ppid and pid members, respectively.
If the condition in step 7 is not met, it means the current task is running in a container. The code inside the else block assigns the PID namespace ID and mount namespace ID to pid_id and mnt_id members, respectively. It also retrieves the container's PPID and PID from the task's namespace and assigns them to ppid and pid members, respectively.
context->uid = bpf_get_current_uid_gid();: This line retrieves the user ID (UID) associated with the current task using the bpf_get_current_uid_gid() BPF helper function and assigns it to the uid member of the context structure.
bpf_get_current_comm(&context->comm, sizeof(context->comm));: This line retrieves the command name (executable name) associated with the current task and copies it to the comm member of the context structure. The sizeof(context->comm) specifies the size of the destination buffer.
Finally, the function returns 0, indicating successful initialization of the context.
Overall, the init_context function initializes the sys_context_t structure by populating its members with relevant context information obtained from the current task.
context.argnum = get_arg_num(types);
context.retval = PT_REGS_RC(ctx);
context.argnum = get_arg_num(types);: This line calls the get_arg_num function with the types argument and assigns the returned value to the argnum member of the context structure. The types variable represents a bitmask of argument types, which determines the number of arguments present in the function call. The get_arg_num function calculates the number of arguments based on the bitmask and returns the result.
static __always_inline int get_arg_num(u64 types)
{
unsigned int i, argnum = 0;
#pragma unroll
for (i = 0; i < MAX_ARGS; i++)
{
if (DEC_ARG_TYPE(i, types) != NONE_T)
argnum++;
}
return argnum;
}
The code snippet shows the implementation of the get_arg_num function. This function takes a bitmask types as an argument and returns the number of arguments based on the bitmask.
Here’s how the function works:
It initializes two variables: i for the loop counter and argnum to keep track of the number of arguments.
The for loop iterates over MAX_ARGS number of times. MAX_ARGS is a constant defined as 6 code, representing the maximum number of arguments.
Inside the loop, it checks the argument type for each position i in the bitmask using the DEC_ARG_TYPE(i, types) macro. The DEC_ARG_TYPE macro extracts the argument type from the bitmask based on the position i.
If the argument type is not NONE_T (indicating that there is an argument at that position), it increments the argnum counter.
After the loop, it returns the final value of argnum, which represents the total number of arguments present in the bitmask.
In summary, the get_arg_num function iterates over the bitmask of argument types and counts the number of non-zero argument types, returning the total count as the result.
if (context.retval >= 0 && drop_syscall(_NETWORK_PROBE))
{
return 0;
}
context.retval >= 0: This condition checks if the value of context.retval (which represents the return value of a system call) is greater than or equal to 0. This condition ensures that the system call executed successfully.
drop_syscall(_NETWORK_PROBE): This condition calls the drop_syscall function with the _NETWORK_PROBE scope as an argument. If this function returns a non-zero value, indicating that the system call should be dropped, the condition evaluates to true.
If both conditions are true, meaning the system call executed successfully and should be dropped based on the provided scope, the code block within the if statement will be executed.
enum
{
_FILE_PROBE = 0,
_PROCESS_PROBE = 1,
_NETWORK_PROBE = 2,
_CAPS_PROBE = 3,
_TRACE_SYSCALL = 0,
_IGNORE_SYSCALL = 1,
};
struct outer_key
{
u32 pid_ns;
u32 mnt_ns;
};
static __always_inline u32 drop_syscall(u32 scope)
{
struct outer_key okey;
struct task_struct *task = (struct task_struct *)bpf_get_current_task();
get_outer_key(&okey, task);
u32 *ns_visibility = bpf_map_lookup_elem(&kubearmor_visibility, &okey);
if (!ns_visibility)
{
return _TRACE_SYSCALL;
}
u32 *on_off_switch = bpf_map_lookup_elem(ns_visibility, &scope);
if (!on_off_switch)
{
return _TRACE_SYSCALL;
}
if (*on_off_switch)
return _IGNORE_SYSCALL;
return _TRACE_SYSCALL;
}
static __always_inline void get_outer_key(struct outer_key *pokey,
struct task_struct *t)
{
pokey->pid_ns = get_task_pid_ns_id(t);
pokey->mnt_ns = get_task_mnt_ns_id(t);
if (pokey->pid_ns == PROC_PID_INIT_INO)
{
pokey->pid_ns = 0;
pokey->mnt_ns = 0;
}
}
The drop_syscall function is used to determine whether a syscall should be dropped or traced based on the provided scope.
Here’s a breakdown of the function:
It starts by defining a structure struct outer_key and obtaining the current task using bpf_get_current_task().
The function then calls get_outer_key to populate the okey structure with relevant information based on the current task.
It looks up the value associated with the okey in the kubearmor_visibility map using bpf_map_lookup_elem. If the lookup fails (!ns_visibility), it returns _TRACE_SYSCALL, indicating that the syscall should be traced.
Next, it looks up the value associated with the scope in the ns_visibility map using bpf_map_lookup_elem. If the lookup fails (!on_off_switch), it returns _TRACE_SYSCALL, again indicating that the syscall should be traced.
If the lookup succeeds, it checks the value pointed to by on_off_switch. If it is non-zero (*on_off_switch is true), it returns _IGNORE_SYSCALL, indicating that the syscall should be dropped.
If none of the previous conditions are met, it returns _TRACE_SYSCALL, indicating that the syscall should be traced.
Overall, this function is responsible for determining whether a syscall should be dropped or traced based on the provided scope and the information stored in the kubearmor_visibility map.
10.Here’s a brief explanation of these lines:
if (get_connection_info(&conn, &sockv4, &sockv6, &context, &args, _TCP_CONNECT) != 0)
{
return 0;
}
This snippet checks the return value of the function get_connection_info against zero. If the return value is not equal to zero, the code block within the if statement is executed, and the function or block of code that contains this snippet returns 0.
- Here’s a brief explanation of these lines:
args.args[0] = (unsigned long)conn.skc_prot->name;
The code snippet assigns the value of conn.skc_prot->name to args.args[0]. It appears that args is a structure or array with a member called args, which is an array or a structure itself.
By using (unsigned long)conn.skc_prot->name, it converts the value of conn.skc_prot->name to an unsigned long type and assigns it to args.args[0].
- Here’s a brief explanation of these lines:
set_buffer_offset(DATA_BUF_TYPE, sizeof(sys_context_t));
In this specific case, the function call set_buffer_offset(DATA_BUF_TYPE, sizeof(sys_context_t)) updates the value of the element in the bufs_offset array with the index DATA_BUF_TYPE (0). The new value assigned to that element is the size of the sys_context_t structure, obtained using sizeof(sys_context_t).
Required definiton
#define DATA_BUF_TYPE 0
#define EXEC_BUF_TYPE 1
#define FILE_BUF_TYPE 2
static __always_inline void set_buffer_offset(int buf_type, u32 off)
{
bpf_map_update_elem(&bufs_offset, &buf_type, &off, BPF_ANY);
}
The set_buffer_offset function takes two arguments: buf_type (the buffer type) and off (the offset value). It updates the corresponding element in the bufs_offset array with the provided off value using the bpf_map_update_elem function.
BPF_PERCPU_ARRAY(bufs_offset, u32, 3);
There is a BPF per-CPU array named bufs_offset defined with a size of 3. This array is used to store the offset values for different buffer types.
This code is useful for maintaining and accessing offset values associated with different buffer types in the BPF program. It allows the BPF program to efficiently calculate the memory locations for specific buffer types based on the provided offsets.
- Here’s a brief explanation of these lines:
bufs_t *bufs_p = get_buffer(DATA_BUF_TYPE);
It declares a pointer variable bufs_p of type bufs_t*, and assigns it the value returned by the get_buffer function when called with the DATA_BUF_TYPE parameter.
The get_buffer function, retrieves an element from the bufs map based on the provided buffer type. Since bufs_p is assigned the returned pointer, it will point to the bufs_t structure corresponding to the DATA_BUF_TYPE in the bufs map.
This allows you to access and manipulate the data stored in the buffer through the bufs_p pointer.
Required definition
typedef struct buffers
{
u8 buf[MAX_BUFFER_SIZE];
} bufs_t;
static __always_inline bufs_t *get_buffer(int buf_type)
{
return bpf_map_lookup_elem(&bufs, &buf_type);
}
The code snippet defines a structure bufs_t that contains a byte array buf with a maximum size defined by MAX_BUFFER_SIZE.
The get_buffer function is declared as an inline function, which is always inlined at the call site to optimize performance. This function takes an integer parameter buf_type and returns a pointer to a bufs_t structure.
Within the get_buffer function, bpf_map_lookup_elem is used to retrieve an element from the bufs map.The first parameter of bpf_map_lookup_elem is the map object (&bufs), and the second parameter is the key used to lookup the element (&buf_type).
The function returns a pointer to the retrieved bufs_t structure.
BPF_PERCPU_ARRAY(bufs, bufs_t, 3);
The code snippet declares a BPF per-CPU array named bufs that can store elements of type bufs_t. The array has a size of 3, indicating that it can hold three elements.
A BPF per-CPU array is an array data structure in eBPF that allows each CPU to have its own private copy of the array. This is useful in scenarios where concurrent access to the array from multiple CPUs needs to be managed efficiently.
In this case, the bufs array is defined to store elements of type bufs_t, which is a structure containing a byte array buf with a maximum size defined by MAX_BUFFER_SIZE.
By declaring a per-CPU array, the BPF program can efficiently store and access buffers of type bufs_t per CPU. Each CPU will have its own private copy of the array,` enabling concurrent access without requiring synchronization mechanisms.
- Here’s a brief explanation of these lines:
if (bufs_p == NULL)
return 0;
Checks if the bufs_p pointer is NULL, indicating that the corresponding buffer was not found in the bufs map.
If bufs_p is NULL, it means that the buffer retrieval failed, and the code returns 0 to indicate an error or failure condition.
- Here’s a brief explanation of these lines:
save_context_to_buffer(bufs_p, (void *)&context);
save_context_to_buffer(bufs_p, (void *)&context); calls the save_context_to_buffer function with bufs_p as the buffer pointer and (void *)&context as the pointer to the context data.
The function save_context_to_buffer attempts to save the context data pointed to by (void *)&contextinto the buffer pointed to bybufs_p.` If the save operation is successful, it returns the size of the context data (sizeof(sys_context_t).
Where , save_context_to_buffer is defined as
static __always_inline int save_context_to_buffer(bufs_t *bufs_p, void *ptr)
{
if (bpf_probe_read(&(bufs_p->buf[0]), sizeof(sys_context_t), ptr) == 0)
{
return sizeof(sys_context_t);
}
return 0;
}
The function save_context_to_buffer is used to save the context data pointed to by ptr into the buffer bufs_p. Here’s how the function works:
It attempts to read the data from ptr using bpf_probe_read and stores it in the buffer bufs_p->buf[0]. The size of the data being read is sizeof(sys_context_t).
If the read operation succeeds (indicated by bpf_probe_read returning 0), it returns sizeof(sys_context_t) to indicate the number of bytes saved to the buffer.
If the read operation fails (indicated by bpf_probe_read returning a non-zero value), it returns 0 to indicate that the save operation failed.
Overall, the function attempts to save the context data to the buffer and returns the number of bytes saved if successful, or 0 if it fails.
- Here’s a brief explanation of these lines:
save_args_to_buffer(types, &args);
save_args_to_buffer(types, &args); is a function call to the save_args_to_buffer function, which is responsible for saving the arguments to the buffer.
In this function call, types is a variable representing the types of arguments, and args is a pointer to the args_t structure that holds the argument values.
By calling save_args_to_buffer(types, &args), the function will process the arguments based on their types and save them to the buffer.
static __always_inline int save_args_to_buffer(u64 types, args_t *args)
{
if (types == 0)
{
return 0;
}
bufs_t *bufs_p = get_buffer(DATA_BUF_TYPE);
if (bufs_p == NULL)
{
return 0;
}
#pragma unroll
for (int i = 0; i < MAX_ARGS; i++)
{
switch (DEC_ARG_TYPE(i, types))
{
case NONE_T:
break;
case INT_T:
save_to_buffer(bufs_p, (void *)&(args->args[i]), sizeof(int), INT_T);
break;
case OPEN_FLAGS_T:
save_to_buffer(bufs_p, (void *)&(args->args[i]), sizeof(int), OPEN_FLAGS_T);
break;
case FILE_TYPE_T:
save_file_to_buffer(bufs_p, (void *)args->args[i]);
break;
case PTRACE_REQ_T:
save_to_buffer(bufs_p, (void *)&(args->args[i]), sizeof(int), PTRACE_REQ_T);
break;
case MOUNT_FLAG_T:
save_to_buffer(bufs_p, (void *)&(args->args[i]), sizeof(int), MOUNT_FLAG_T);
break;
case UMOUNT_FLAG_T:
save_to_buffer(bufs_p, (void *)&(args->args[i]), sizeof(int), UMOUNT_FLAG_T);
break;
case STR_T:
save_str_to_buffer(bufs_p, (void *)args->args[i]);
break;
case SOCK_DOM_T:
save_to_buffer(bufs_p, (void *)&(args->args[i]), sizeof(int), SOCK_DOM_T);
break;
case SOCK_TYPE_T:
save_to_buffer(bufs_p, (void *)&(args->args[i]), sizeof(int), SOCK_TYPE_T);
break;
case SOCKADDR_T:
if (args->args[i])
{
short family = 0;
bpf_probe_read(&family, sizeof(short), (void *)args->args[i]);
switch (family)
{
case AF_UNIX:
save_to_buffer(bufs_p, (void *)(args->args[i]), sizeof(struct sockaddr_un), SOCKADDR_T);
break;
case AF_INET:
save_to_buffer(bufs_p, (void *)(args->args[i]), sizeof(struct sockaddr_in), SOCKADDR_T);
break;
case AF_INET6:
save_to_buffer(bufs_p, (void *)(args->args[i]), sizeof(struct sockaddr_in6), SOCKADDR_T);
break;
default:
save_to_buffer(bufs_p, (void *)&family, sizeof(short), SOCKADDR_T);
}
}
break;
case UNLINKAT_FLAG_T:
save_to_buffer(bufs_p, (void *)&(args->args[i]), sizeof(int), UNLINKAT_FLAG_T);
break;
}
}
return 0;
}
The code snippet is the definition of the save_args_to_buffer function. This function is responsible for saving the arguments (args) to the buffer.
Here’s a breakdown of what the code does:
- It checks if the
types value is zero. If it is, it returns 0 indicating that there are no arguments to save. - It obtains a pointer to the buffer of type
bufs_t by calling the get_buffer function with DATA_BUF_TYPE as the argument. If the buffer pointer is NULL, it returns 0 indicating a failure. - It then iterates over the arguments using a loop.
Inside the loop, it switches on the argument type determined by
DEC_ARG_TYPE(i, types) where i is the current iteration index. Based on the argument type, different actions are taken:
- For argument types such as
INT_T, OPEN_FLAGS_T, PTRACE_REQ_T, MOUNT_FLAG_T, UMOUNT_FLAG_T, SOCK_DOM_T, SOCK_TYPE_T, and UNLINKAT_FLAG_T, it calls the save_to_buffer function to save the argument value to the buffer with the corresponding size and type. - For
FILE_TYPE_T and STR_T, it calls the save_file_to_buffer and save_str_to_buffer functions respectively to save the argument values to the buffer. - For
SOCKADDR_T, it checks the address family and based on the family value, it saves the appropriate struct sockaddr data to the buffer. - After iterating over all the arguments, it returns 0 indicating a successful save.
- Overall, the
save_args_to_buffer function is responsible for saving the arguments to the buffer based on their types.
17.Here’s a brief explanation of these lines:
static __always_inline int events_perf_submit(struct pt_regs *ctx)
{
bufs_t *bufs_p = get_buffer(DATA_BUF_TYPE);
if (bufs_p == NULL)
return -1;
u32 *off = get_buffer_offset(DATA_BUF_TYPE);
if (off == NULL)
return -1;
void *data = bufs_p->buf;
int size = *off & (MAX_BUFFER_SIZE - 1);
return bpf_perf_event_output(ctx, &sys_events, BPF_F_CURRENT_CPU, data, size);
}
The code is the implementation of the events_perf_submit function. This function is responsible for submitting events to a BPF perf event output buffer.
Here’s a breakdown of the code:
bufs_t *bufs_p = get_buffer(DATA_BUF_TYPE);: It retrieves a pointer to the buffer of type DATA_BUF_TYPE using the get_buffer function. If the buffer is not found or is NULL, it returns -1.
u32 *off = get_buffer_offset(DATA_BUF_TYPE);: It retrieves the offset value for the DATA_BUF_TYPE buffer using the get_buffer_offset function. If the offset is not found or is NULL, it returns -1.
void *data = bufs_p->buf;: It assigns the starting address of the buffer to the data pointer.
int size = *off & (MAX_BUFFER_SIZE - 1);: It calculates the size of the data in the buffer by masking the offset value with MAX_BUFFER_SIZE - 1. This ensures that the size is within the maximum buffer size.
return bpf_perf_event_output(ctx, &sys_events, BPF_F_CURRENT_CPU, data, size);: It submits the event to the BPF perf event output buffer using the bpf_perf_event_output function. The ctx parameter is a pointer to struct pt_regs, &sys_events is the BPF map representing the perf event output buffer, BPF_F_CURRENT_CPU specifies the CPU to submit the event to, data is the pointer to the data buffer, and size is the size of the data. The function returns the result of the submission.
Overall, the events_perf_submit function retrieves the buffer and offset, prepares the data and size, and then submits the event to the perf event output buffer.














 Use the downloaded file to install gitsign.
Use the downloaded file to install gitsign.












 .
. .
. .
.


















 This is a simple example, but it demonstrates how you can use Terratest to automate the testing of your Terraform modules.
This is a simple example, but it demonstrates how you can use Terratest to automate the testing of your Terraform modules.